- Dutch
- Frisian
- Saterfrisian
- Afrikaans
-
- Phonology
- Segment inventory
- Phonotactics
- Phonological processes
- Phonology-morphology interface
- Word stress
- Primary stress in simplex words
- Monomorphemic words
- Diachronic aspects
- Generalizations on stress placement
- Default penultimate stress
- Lexical stress
- The closed penult restriction
- Final closed syllables
- The diphthong restriction
- Superheavy syllables (SHS)
- The three-syllable window
- Segmental restrictions
- Phonetic correlates
- Stress shifts in loanwords
- Quantity-sensitivity
- Secondary stress
- Vowel reduction in unstressed syllables
- Stress in complex words
- Primary stress in simplex words
- Accent & intonation
- Clitics
- Spelling
- Morphology
- Word formation
- Compounding
- Nominal compounds
- Verbal compounds
- Adjectival compounds
- Affixoids
- Coordinative compounds
- Synthetic compounds
- Reduplicative compounds
- Phrase-based compounds
- Elative compounds
- Exocentric compounds
- Linking elements
- Separable complex verbs (SCVs)
- Gapping of complex words
- Particle verbs
- Copulative compounds
- Derivation
- Numerals
- Derivation: inputs and input restrictions
- The meaning of affixes
- Non-native morphology
- Cohering and non-cohering affixes
- Prefixation
- Suffixation
- Nominal suffixation: person nouns
- Conversion
- Pseudo-participles
- Bound forms
- Nouns
- Nominal prefixes
- Nominal suffixes
- -aal and -eel
- -aar
- -aard
- -aat
- -air
- -aris
- -ast
- Diminutives
- -dom
- -een
- -ees
- -el (nominal)
- -elaar
- -enis
- -er (nominal)
- -erd
- -erik
- -es
- -eur
- -euse
- ge...te
- -heid
- -iaan, -aan
- -ief
- -iek
- -ier
- -ier (French)
- -ière
- -iet
- -igheid
- -ij and allomorphs
- -ijn
- -in
- -ing
- -isme
- -ist
- -iteit
- -ling
- -oir
- -oot
- -rice
- -schap
- -schap (de)
- -schap (het)
- -sel
- -st
- -ster
- -t
- -tal
- -te
- -voud
- Verbs
- Adjectives
- Adverbs
- Univerbation
- Neo-classical word formation
- Construction-dependent morphology
- Morphological productivity
- Compounding
- Inflection
- Inflection and derivation
- Allomorphy
- The interface between phonology and morphology
- Word formation
- Syntax
- Preface and acknowledgements
- Verbs and Verb Phrases
- 1 Characterization and classification
- 2 Projection of verb phrases I:Argument structure
- 3 Projection of verb phrases II:Verb frame alternations
- Introduction
- 3.1. Main types
- 3.2. Alternations involving the external argument
- 3.3. Alternations of noun phrases and PPs
- 3.3.1. Dative/PP alternations (dative shift)
- 3.3.1.1. Dative alternation with aan-phrases (recipients)
- 3.3.1.2. Dative alternation with naar-phrases (goals)
- 3.3.1.3. Dative alternation with van-phrases (sources)
- 3.3.1.4. Dative alternation with bij-phrases (possessors)
- 3.3.1.5. Dative alternation with voor-phrases (benefactives)
- 3.3.1.6. Conclusion
- 3.3.1.7. Bibliographical notes
- 3.3.2. Accusative/PP alternations
- 3.3.3. Nominative/PP alternations
- 3.3.1. Dative/PP alternations (dative shift)
- 3.4. Some apparent cases of verb frame alternation
- 3.5. Bibliographical notes
- 4 Projection of verb phrases IIIa:Selection of clauses/verb phrases
- 5 Projection of verb phrases IIIb:Argument and complementive clauses
- Introduction
- 5.1. Finite argument clauses
- 5.2. Infinitival argument clauses
- 5.3. Complementive clauses
- 6 Projection of verb phrases IIIc:Complements of non-main verbs
- 7 Projection of verb phrases IIId:Verb clusters
- 8 Projection of verb phrases IV: Adverbial modification
- 9 Word order in the clause I:General introduction
- 10 Word order in the clause II:Position of the finite verb (verb-first/second)
- 11 Word order in the clause III:Clause-initial position (wh-movement)
- Introduction
- 11.1. The formation of V1- and V2-clauses
- 11.2. Clause-initial position remains (phonetically) empty
- 11.3. Clause-initial position is filled
- 12 Word order in the clause IV:Postverbal field (extraposition)
- 13 Word order in the clause V: Middle field (scrambling)
- 14 Main-clause external elements
- Nouns and Noun Phrases
- 1 Characterization and classification
- 2 Projection of noun phrases I: complementation
- Introduction
- 2.1. General observations
- 2.2. Prepositional and nominal complements
- 2.3. Clausal complements
- 2.4. Bibliographical notes
- 3 Projection of noun phrases II: modification
- Introduction
- 3.1. Restrictive and non-restrictive modifiers
- 3.2. Premodification
- 3.3. Postmodification
- 3.3.1. Adpositional phrases
- 3.3.2. Relative clauses
- 3.3.3. Infinitival clauses
- 3.3.4. A special case: clauses referring to a proposition
- 3.3.5. Adjectival phrases
- 3.3.6. Adverbial postmodification
- 3.4. Bibliographical notes
- 4 Projection of noun phrases III: binominal constructions
- Introduction
- 4.1. Binominal constructions without a preposition
- 4.2. Binominal constructions with a preposition
- 4.3. Bibliographical notes
- 5 Determiners: articles and pronouns
- Introduction
- 5.1. Articles
- 5.2. Pronouns
- 5.3. Bibliographical notes
- 6 Numerals and quantifiers
- 7 Pre-determiners
- Introduction
- 7.1. The universal quantifier al 'all' and its alternants
- 7.2. The pre-determiner heel 'all/whole'
- 7.3. A note on focus particles
- 7.4. Bibliographical notes
- 8 Syntactic uses of noun phrases
- Adjectives and Adjective Phrases
- 1 Characteristics and classification
- 2 Projection of adjective phrases I: Complementation
- 3 Projection of adjective phrases II: Modification
- 4 Projection of adjective phrases III: Comparison
- 5 Attributive use of the adjective phrase
- 6 Predicative use of the adjective phrase
- 7 The partitive genitive construction
- 8 Adverbial use of the adjective phrase
- 9 Participles and infinitives: their adjectival use
- 10 Special constructions
- Adpositions and adpositional phrases
- 1 Characteristics and classification
- Introduction
- 1.1. Characterization of the category adposition
- 1.2. A formal classification of adpositional phrases
- 1.3. A semantic classification of adpositional phrases
- 1.3.1. Spatial adpositions
- 1.3.2. Temporal adpositions
- 1.3.3. Non-spatial/temporal prepositions
- 1.4. Borderline cases
- 1.5. Bibliographical notes
- 2 Projection of adpositional phrases: Complementation
- 3 Projection of adpositional phrases: Modification
- 4 Syntactic uses of the adpositional phrase
- 5 R-pronominalization and R-words
- 1 Characteristics and classification
- Phonology
-
- General
- Phonology
- Segment inventory
- Phonotactics
- Phonological Processes
- Assimilation
- Vowel nasalization
- Syllabic sonorants
- Final devoicing
- Fake geminates
- Vowel hiatus resolution
- Vowel reduction introduction
- Schwa deletion
- Schwa insertion
- /r/-deletion
- d-insertion
- {s/z}-insertion
- t-deletion
- Intrusive stop formation
- Breaking
- Vowel shortening
- h-deletion
- Replacement of the glide w
- Word stress
- Clitics
- Allomorphy
- Orthography of Frisian
- Morphology
- Inflection
- Word formation
- Derivation
- Prefixation
- Infixation
- Suffixation
- Nominal suffixes
- Verbal suffixes
- Adjectival suffixes
- Adverbial suffixes
- Numeral suffixes
- Interjectional suffixes
- Onomastic suffixes
- Conversion
- Compositions
- Derivation
- Syntax
- Verbs and Verb Phrases
- Characteristics and classification
- Unergative and unaccusative subjects
- Evidentiality
- To-infinitival clauses
- Predication and noun incorporation
- Ellipsis
- Imperativus-pro-Infinitivo
- Expression of irrealis
- Embedded Verb Second
- Agreement
- Negation
- Nouns & Noun Phrases
- Classification
- Complementation
- Modification
- Partitive noun constructions
- Referential partitive constructions
- Partitive measure nouns
- Numeral partitive constructions
- Partitive question constructions
- Nominalised quantifiers
- Kind partitives
- Partitive predication with prepositions
- Bare nominal attributions
- Articles and names
- Pronouns
- Quantifiers and (pre)determiners
- Interrogative pronouns
- R-pronouns
- Syntactic uses
- Adjective Phrases
- Characteristics and classification
- Complementation
- Modification and degree quantification
- Comparison by degree
- Comparative
- Superlative
- Equative
- Attribution
- Agreement
- Attributive adjectives vs. prenominal elements
- Complex adjectives
- Noun ellipsis
- Co-occurring adjectives
- Predication
- Partitive adjective constructions
- Adverbial use
- Participles and infinitives
- Adposition Phrases
- Characteristics and classification
- Complementation
- Modification
- Intransitive adpositions
- Predication
- Preposition stranding
- Verbs and Verb Phrases
-
- General
- Morphology
- Morphology
- 1 Word formation
- 1.1 Compounding
- 1.1.1 Compounds and their heads
- 1.1.2 Special types of compounds
- 1.1.2.1 Affixoids
- 1.1.2.2 Coordinative compounds
- 1.1.2.3 Synthetic compounds and complex pseudo-participles
- 1.1.2.4 Reduplicative compounds
- 1.1.2.5 Phrase-based compounds
- 1.1.2.6 Elative compounds
- 1.1.2.7 Exocentric compounds
- 1.1.2.8 Linking elements
- 1.1.2.9 Separable Complex Verbs and Particle Verbs
- 1.1.2.10 Noun Incorporation Verbs
- 1.1.2.11 Gapping
- 1.2 Derivation
- 1.3 Minor patterns of word formation
- 1.1 Compounding
- 2 Inflection
- 1 Word formation
- Morphology
- Syntax
- Adjectives and adjective phrases (APs)
- 0 Introduction to the AP
- 1 Characteristics and classification of APs
- 2 Complementation of APs
- 3 Modification and degree quantification of APs
- 4 Comparison by comparative, superlative and equative
- 5 Attribution of APs
- 6 Predication of APs
- 7 The partitive adjective construction
- 8 Adverbial use of APs
- 9 Participles and infinitives as APs
- Nouns and Noun Phrases (NPs)
- 0 Introduction to the NP
- 1 Characteristics and Classification of NPs
- 2 Complementation of NPs
- 3 Modification of NPs
- 3.1 Modification of NP by Determiners and APs
- 3.2 Modification of NP by PP
- 3.3 Modification of NP by adverbial clauses
- 3.4 Modification of NP by possessors
- 3.5 Modification of NP by relative clauses
- 3.6 Modification of NP in a cleft construction
- 3.7 Free relative clauses and selected interrogative clauses
- 4 Partitive noun constructions and constructions related to them
- 4.1 The referential partitive construction
- 4.2 The partitive construction of abstract quantity
- 4.3 The numerical partitive construction
- 4.4 The partitive interrogative construction
- 4.5 Adjectival, nominal and nominalised partitive quantifiers
- 4.6 Kind partitives
- 4.7 Partitive predication with a preposition
- 4.8 Bare nominal attribution
- 5 Articles and names
- 6 Pronouns
- 7 Quantifiers, determiners and predeterminers
- 8 Interrogative pronouns
- 9 R-pronouns and the indefinite expletive
- 10 Syntactic functions of Noun Phrases
- Adpositions and Adpositional Phrases (PPs)
- 0 Introduction to the PP
- 1 Characteristics and classification of PPs
- 2 Complementation of PPs
- 3 Modification of PPs
- 4 Bare (intransitive) adpositions
- 5 Predication of PPs
- 6 Form and distribution of adpositions with respect to staticity and construction type
- 7 Adpositional complements and adverbials
- Verbs and Verb Phrases (VPs)
- 0 Introduction to the VP in Saterland Frisian
- 1 Characteristics and classification of verbs
- 2 Unergative and unaccusative subjects and the auxiliary of the perfect
- 3 Evidentiality in relation to perception and epistemicity
- 4 Types of to-infinitival constituents
- 5 Predication
- 5.1 The auxiliary of being and its selection restrictions
- 5.2 The auxiliary of going and its selection restrictions
- 5.3 The auxiliary of continuation and its selection restrictions
- 5.4 The auxiliary of coming and its selection restrictions
- 5.5 Modal auxiliaries and their selection restrictions
- 5.6 Auxiliaries of body posture and aspect and their selection restrictions
- 5.7 Transitive verbs of predication
- 5.8 The auxiliary of doing used as a semantically empty finite auxiliary
- 5.9 Supplementive predication
- 6 The verbal paradigm, irregularity and suppletion
- 7 Verb Second and the word order in main and embedded clauses
- 8 Various aspects of clause structure
- Adjectives and adjective phrases (APs)
-
- General
- Phonology
- Afrikaans phonology
- Segment inventory
- Overview of Afrikaans vowels
- The diphthongised long vowels /e/, /ø/ and /o/
- The unrounded mid-front vowel /ɛ/
- The unrounded low-central vowel /ɑ/
- The unrounded low-central vowel /a/
- The rounded mid-high back vowel /ɔ/
- The rounded high back vowel /u/
- The rounded and unrounded high front vowels /i/ and /y/
- The unrounded and rounded central vowels /ə/ and /œ/
- The diphthongs /əi/, /œy/ and /œu/
- Overview of Afrikaans consonants
- The bilabial plosives /p/ and /b/
- The alveolar plosives /t/ and /d/
- The velar plosives /k/ and /g/
- The bilabial nasal /m/
- The alveolar nasal /n/
- The velar nasal /ŋ/
- The trill /r/
- The lateral liquid /l/
- The alveolar fricative /s/
- The velar fricative /x/
- The labiodental fricatives /f/ and /v/
- The approximants /ɦ/, /j/ and /ʋ/
- Overview of Afrikaans vowels
- Word stress
- The phonetic properties of stress
- Primary stress on monomorphemic words in Afrikaans
- Background to primary stress in monomorphemes in Afrikaans
- Overview of the Main Stress Rule of Afrikaans
- The short vowels of Afrikaans
- Long vowels in monomorphemes
- Primary stress on diphthongs in monomorphemes
- Exceptions
- Stress shifts in place names
- Stress shift towards word-final position
- Stress pattern of reduplications
- Phonological processes
- Vowel related processes
- Consonant related processes
- Homorganic glide insertion
- Phonology-morphology interface
- Phonotactics
- Morphology
- Syntax
- Afrikaans syntax
- Nouns and noun phrases
- Characteristics of the NP
- Classification of nouns
- Complementation of NPs
- Modification of NPs
- Binominal and partitive constructions
- Referential partitive constructions
- Partitive measure nouns
- Numeral partitive constructions
- Partitive question constructions
- Partitive constructions with nominalised quantifiers
- Partitive predication with prepositions
- Binominal name constructions
- Binominal genitive constructions
- Bare nominal attribution
- Articles and names
- Pronouns
- Quantifiers, determiners and predeterminers
- Syntactic uses of the noun phrase
- Adjectives and adjective phrases
- Characteristics and classification of the AP
- Complementation of APs
- Modification and Degree Quantification of APs
- Comparison by comparative, superlative and equative degree
- Attribution of APs
- Predication of APs
- The partitive adjective construction
- Adverbial use of APs
- Participles and infinitives as adjectives
- Verbs and verb phrases
- Characterisation and classification
- Argument structure
- Verb frame alternations
- Complements of non-main verbs
- Verb clusters
- Complement clauses
- Adverbial modification
- Word order in the clause: Introduction
- Word order in the clause: position of the finite Verb
- Word order in the clause: Clause-initial position
- Word order in the clause: Extraposition and right-dislocation in the postverbal field
- Word order in the middle field
- Emphatic constructions
- Adpositions and adposition phrases
See the following sections for notational conventions and symbols used when presenting examples on the Afrikaans Taalportaal:
- In running text, examples are usually followed by either translations, or glosses and translations, although other annotations (like phonetic transcriptions, or morphological analyses) could also be added to examples in running text.
- Example, followed by translation: hond dog
- Example, followed by gloss and translation: hond·e dog·PL dogs
- With regard to examples, glosses and translation, note the following:
- Morpheme boundaries and morphemic glosses are only provided where it is relevant to the discussion.
- Examples in a list or as part of a table (e.g. a list with all examples of words in Afrikaans that begins with [ɦɔ], or a complete lists of words ending in -teit) are not necessarily annotated with glosses and/or translations – especially in contexts where it is either not relevant to the discussion, or where the list is merely illustrative of the matter under discussion.
extraSoftware-specific: ling.dita 2.4 in oXygen (XML)- Larger datasets and tables should be placed in <extra>.
- Examples in a series in an unincorporated clause in running text are separated by semicolons, e.g. loop to walk; sit to sit; staan to stand. However, if the examples are incorporated in the sentence, they are separated by commas, e.g.: "Verbs like loop to walk, sit to sit and staan to stand are called motion verbs." Examples larger than words (e.g. phrases) are mostly presented in bullet lists.
- In running text, a list of examples are each presented in their own <lexample>.
- Correct: … as illustrated by words like pad; kat; pan; and dam.
- Wrong: … as illustrated by words like pad; kat; pan; and dam.
- Examples and linguistic material (such as glosses, translations, and other annotations) are presented in a consistent sequence, in order to make it easier for the reader to follow across modules and topics. This sequence is as follow, where one or more of the annotation levels could be omitted:
- Example
- [Phonetic transcription]
- /Phonological analysis/
- [Morphological analysis]
- [Syntactical analysis]
- Gloss
- Translation
- Source/cross-reference
- [Comment by author]
- If ever an example with all nine these fields would occur, it might look like this: 1
die hond·e op die wandel+paai·e (< wandel+pad·e) [di ˈɦɔ.nə ɔ.pi ˈvɑn.əlˌpaiʲə] /di ˈɦɔn.də ɔp di ˈvan.dəlˌpai.ə/ die [[hond](N)[e](PL)](N) op die [[[wandel](V)[pad](N)](N)[e](PL)](N) [(NP) die honde op die wandelpaaie] the dog·PL on the walk+road·PL the dogs on the hiking trail (SkalkSkryf, 2011/02/17) [This example is used to illustrate different levels of annotation.] - When a proper name is presented as an example, its gloss and/or translation could be indicated with id., e.g. Pietermaritzburg id..
- Examples from other languages (e.g. Latin, Greek, English, Dutch) is presented like this: Latin ducereto bring.
- When writing Latin or transliterated Greek words, diacritics are generally not used, e.g. ordo instead of ōrdō
extraSoftware-specific: ling.dita 2.4 in oXygen (XML)- Words from other languages than Afrikaans are marked-up with <lexterm><word>, and not with <lexample>.
- The only environment where Afrikaans words are marked-up with <lexterm><word>, is in headers where <lexample> is not possible, e.g.: Examples with opon.
- When using Afrikaans words/phrases in different text environments, the following formatting should be used:
- Title (topic/section): infinitive with om te; or dit extraposition
- Running text: infinitive with om te; or dit extraposition
- Header: infinitive with om te; or dit extraposition (since <lexample> is not possible as explained above).
- Keyword, or part of a keyword: <keyword>infinitive with "om te"</keyword>; or <keyword>"dit" extraposition</keyword> (i.e. write it between double quotation marks).
- An asterisk ( * ) is used to mark ungrammatical examples, e.g. *interesant
- A question mark ( ? ) is used to mark questionable examples, e.g. ?noninteressant
- To indicate an ungrammatical example, type a * before the word/sentence, as part of the <wordgroup>. Don't use attribute:judgement = ungrammatical.
- To indicate a questionable example, type a ? before the word/sentence, as part of the <wordgroup>. Don't use attribute:judgement = doubtful.
- Translations of verbs start with “to…”, e.g. ver·huis to move (to another house).
- When presenting a numbered example where italics (or similar formatting) was used in the original text to indicate words in their self-naming function, use a combination of <emphasis> and quotation marks, e.g.:
- 1
Die woord beeldskoon kan trappe van vergelyking neem, soos wat die skrywer duidelik illustreer met: "Dit was die beeldskoonste sonsondergang ooit!". - When referring to examples in running text only the example number and parentheses are highlighted and then linked to the example.
- Example: Another prominent group of words that can be motivated in terms of univerbation, is so-called pronominal adverbs, as in example (7a).
- NB: Remember that these example numbers in the running text don't update automatically if you add other examples at the beginning of the text. The number of the example will change though. All example numbers should be manually checked before committing the final topic.
- When referring to sub-examples in running text, include the number and letter between parentheses, e.g. (7a), (18c), etc.
- Don't put the numbers and letters between separate parentheses, e.g. *(7a), *(18c)
- Where possible, the Leipzig Glossing Rules for glossing of examples are strictly followed. However, note the following important change to their rule 2:
- Segmentable morphemes are separated by middle dots, both in the example and in the gloss. There must be exactly the same number of middle dots in the example and in the gloss.
- Hence, where one might find, for example, hond-e dog-PL dogs in a document strictly following the Leipzig rules, the same word is presented here with a middle dot instead of a hyphen, as in hond·e dog·PL dogs. (Also see the section on morphology below.)
- Where glossing abbreviations are not available in the Leipzig Glossing Rules, abbreviations used generally in linguistic descriptions are used. For ease of reference, see the comprehensive table of glossing abbreviations, as well as the table of common combinations of glossing abbreviations.
- Even if an example sentence starts with a capital letter, the gloss is written in small letters (but the translation then with a capital letter again). The same also applies to punctuation marks – no sentential punctuation (except eclipses depicting omissions in the middle of a sentence, but not at the periphery) are used in glosses, e.g. Hoe ... laat is dit? how ... late is it What ... time is it?
- R-pronouns are typically glossed as follow:
- daar·op PN·on on it/that
- hier·op PN·on on it/this
- waar·op REL·on on which
- Graphemes, grapheme clusters, and spelling forms: h; spr; spr...; hond; ...nd
- Phones and phonetic transcriptions: [ɦ]; [ɦɔnt]
- Phonemes and phonological analyses: /ɦ/; /ɦɔnt/
- Distinctive features: +son; -nasal
- When stating a feature specification of a particular sound, the distinctive features are included in one set of brackets, e.g.: A possible feature specification of /x/ is +cons, -son, -syll, -labial, -cor, +dorsal, +high, -low, +back, -tense, -pharyngeal, -voice, +cont, -strident, -lateral, -del rel, -nasal.
- To indicate stress using orthographic signs (i.e. not using IPA symbols in phonetic transcription), acute accents on vowels of the stressed syllable are used, as prescribed in AWS-11. E.g.:
- táfel
- bóódskap
- aanhóúdend
- vliégskool
- opvliéënd
- Morphemes and morphological analyses: -e; [[hond](N)[e](CN.PL)](N)
- By default, all morphemes are written between square brackets, and provided with a functional category in subscript, e.g. [[on](CN)[[mens](N)[lik](ADJZ)](ADJ)](ADJ). However, this could also be short-handed, depending on the purpose of the description, e.g. [on[[mens](N)lik]](ADJ).
- In morphological analyses, allomorphs are presented in their original form, but roots are written and marked as roots, e.g.
- leiding is analysed as [[lei](V)[ing](NMLZ)](N)
- skape is analysed as [[skaap](N)[e](PL)](N)
- radikaal is analysed as [[radik](root)[aal](ADJZ)](ADJ)
- However, if stem allomorphy occurs due to the addition of an interfix, the resulting allomorph is not explicitly marked, e.g. passasier·s+boot is analysed as [[[passassier](N)[s](LK)][boot]](N)
- Synchronic vs. diachronic analysesBy default, all analyses are done from a synchronic perspective, i.e. the way the average, informed person would perceive a word.
- For example, although probleem could be analysed as [[pro][bleem]] from a diachronic perspective, it is rather seen synchronically as a simplex (i.e. [probleem]).
- In cases where it is necessary to analyse words from a diachronic perspective (e.g. with regard to bound forms, non-native morphology, etc.), such words could of course be analysed in more detail, for example [[on](ADJZ)[[[pro](NMLZ)[blem](root)](N)[at](LK)[ies](ADJZ)](ADJ)](ADJ)
- Forms of the verbNote the following terminology and conventions regarding verbal morphology:
- The following forms of a verb are distinguished:
- base/base form/base word = breek break to break
- Depending on the context and/or purpose of the discussion, it could also be glossed as break.PRS or break.INF.
- past tense form = ge·breek PST·break.
- The view in the Afrikaans morphology section of Taalportaal is that this form of the verb only occurs in the periphrastic past tense construction with het have.AUX (see Butler 2016).
- passive voice form = ge·breek PASS·break broken
- The view in the Afrikaans morphology section of Taalportaal is that this form of the verb only occurs in the periphrastic passive voice construction with either word be.AUX.PASS.PRS is, or is be.AUX.PASS.PST was (see Butler 2016).
- present participle form = brek·end (< breek·end break·PRS.PTCP breaking)
- past participle form (strong verb) = gebroke break.PST.PTCP broken.
- past participle form (weak verb) = ge·breek PST.PTCP·break broken, or ge·breek·t·e PST.PTCP·break·PST.PTCP·ATTR broken
- Participles don't function as verbs, but rather as adjectives (e.g. brek·end·e branders breaking waves), nouns (e.g. die in+sitt·end·e the in+sit·PRS.PTCP·ATTR the passenger), or prepositions (e.g. hang·end·e hang·PRS.PTCP·ATTR pending).
- See the sections on conversion with adjectives as input category, and prepositions as output category. Also see the section on pseudo-participles in Afrikaans.
- Note that in some sections in the Afrikaans Taalportaal – specifically some sections of the verb phrase – a different stance is taken with regard to participles. There the past tense and passive voice forms are considered to be participles.
Figure 1: Different forms of the verb (Butler 2016)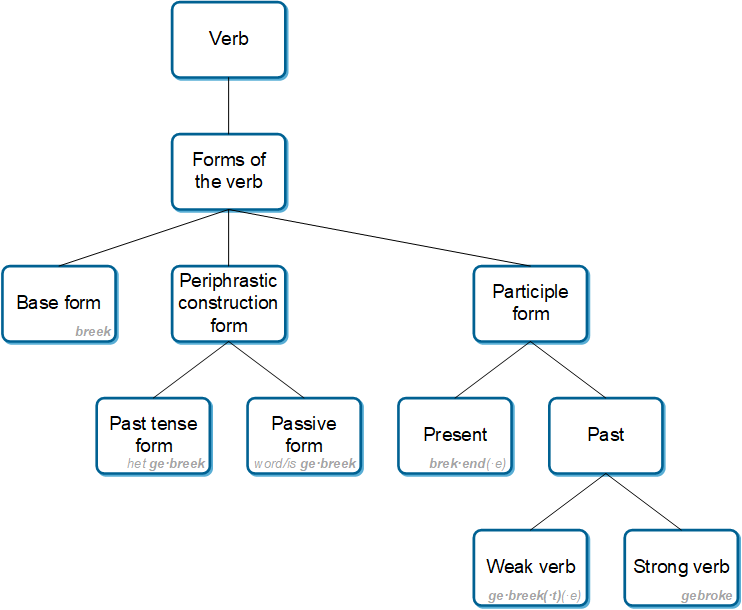 [click image to enlarge]
[click image to enlarge] - base/base form/base word = breek break to break
- If one takes a fine-grained, morpheme-based approach to morphological analysis, one could say that Afrikaans participles are formed through circumfixation, as discussed elaborately here. From this viewpoint, the participial circumfix is ge-...-t/d, with the allomorphs ge-...-ø, ø-...-t/d, and ø-...-ø. A simpler, more coarse-grained approach is to say that past participles in Afrikaans is formed by either a circumfix ge-...-t/d, a prefix ge-, a suffix -d/t, or by using the base as participle. Of course, these two perspectives are not in conflict with each other, and will be used for different purposes in the Afrikaans morphology section of Taalportaal.
- The following forms of a verb are distinguished:
- A double arrow ( ↔ ) is used to separate form (on the left-hand side) and meaning (on the right-hand side), e.g. [[hond](N)[e](PL)](N) ↔ [more than one SEM(N)].
- Read this as follows: With regard to the form of the word, the noun (N)hond is suffixed with a plural (PL)-e; the resulting word is a noun (N). This form means: 'more than one of the semantic notion (SEM) of the noun (N) in the form.
- The ellipse ( ... ) is used to indicate schematic, unspecified content, e.g.:
- [...·ing] is schematic for words ending with the suffix -ing, e.g. werk·ing, be·mark·ing, and ont·boss·ing;
- [...ing] is schematic for words ending in the letters ing, like koning, werk·ing, and twee·ling
- We see /r/ deletion in the following contexts: per...; ter...; for...
- A hyphen is used to mark:
- an affix in running text, with the position of the hyphen implicitly indicating whether it is a prefix (on-), suffix (-agtig), interfix (-e-), or circumfix (ge-...-te); and
- a bound form, root, confix, or splinter, e.g. radik-, -logie or -gate. Since the hyphen ( - ) plays an important role in the orthography of Afrikaans, it is always treated as a grapheme; in some cases, for the sake of brevity, we also use the hyphen as a demarcation symbol, e.g. the orthographic form pa-hulle might be glossed as dad-3PL instead of pa·-·hulle dad·LK·3PL.
- An interpunct (·) (a.k.a. an interpoint, middle dot, middot, centered dot, etc.) is used to indicate morpheme boundaries in examples and glosses, but not in morphological analyses (where they are usually enclosed in square brackets), e.g. hond·e. This convention follows that of Bauer (2003).
- The "plus" sign (+) is used to indicate stem boundaries in compounds in examples and glosses, but not in morphological analyses (where they are usually enclosed in square brackets), e.g.:
- Compound: skaap+hond sheep+dog sheperd dog
- Compound with an interfix (a.k.a. linker): hond·e+hok dog·LK+cage kennel
- Separable complex verb: op+gooi up+throw to vomit > op+ge·gooi up+PST·throw vomit.PST
- An underscore ( _ ) is used to indicate univerbations, e.g. onder_weg under_way under-way.
- The division sign (÷) is used to indicate affixoids, e.g. plant÷kundige plant÷expert botanist.
- A full-stop (. ) is used:
- to annotate suppletions (e.g. was be.PST, or nader close.CMPR);
- when a single word in Afrikaans is represented by two words in English (e.g. mekaar each.other); or
- sometimes when it is unimportant in the context to provide a full morphological analysis (e.g. kernuitwissing nuclear.extinction, or stroois straw.house).
- The equal sign ( = ) is used to mark:
- enclitic forms (as prescribed in the Leipzig glossing rules), e.g. hy=t he=have.AUX he has;
- blends, e.g. mo=tel motor=hotel motel).
- Curly brackets ( { } ) are used to indicate clipped parts of words, e.g. admin [admin{istrasie}] administration.
- The slash ( / ) is used when presenting multiple functional categories in running text, e.g. N/V/ADJ.
- The pipe ( | ) is used when presenting multiple functional categories in morphological analyses, e.g. (N|V|ADJ).
- Angle brackets ( < and > ) are used to indicate the direction of morphonological or morphographical change, e.g.:
- drama > drama·t·ies
- skap·e < skaap·e
- ball·e < bal·e
- regt·ig < reg
extraSoftware-specific: ling.dita 2.4 in oXygen (XML)- In an <ilexample>, the angle bracket and the subsequent string should be written within the <wordgroup> tag, otherwise it won't display correctly.
- In addition, this extra information should be provided between round brackets.
- If necessary, <emphasis> could be used to make links between relevant words clear.
i
- NMLZ = nominaliser
- VBZ = verbaliser
- ADJZ = adjectiviser
- ADVZ = adverbialiser
- CN = category-neutral affix (a.k.a. word-class preserving/maintaining affix)
- Note that in the case of category-neutral affixes, the glossing is oftentimes short-handed by excluding CN, and only using the abbreviation for the functional category, e.g. instead of hond·e dog·CN.PL dogs, we often simply write hond·e dog·PL dogs.
- root (e.g. administr-, or sekretar-)
- LK (linker/interfix; e.g. -s- of -e-)
- cran (cranberry morpheme; e.g. boe- in boepens paunch)
- char (characters; e.g. 4x4 in 4x4-voertuig 4x4 vehicle, or R in R-waarde R value, or % in %-teken % sign)
- allo (allomorph; e.g. fakulteit·s in fakulteit·s+raad, where the -s- is an interfix that creates an allomorph of the base word fakulteit faculty, which can then concatenate with raad board)
| venster⋅s | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| window⋅PL | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| windows | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Identical vowel deletion | |||||||||||||||||||||||||||||||||||||||||||||||||
| eet⋅er (> et⋅er) | |||||||||||||||||||||||||||||||||||||||||||||||||
| eat⋅NMLZ | |||||||||||||||||||||||||||||||||||||||||||||||||
| eater | |||||||||||||||||||||||||||||||||||||||||||||||||
| Consonant doubling | |||||||||||||||||||||||||||||||||||||||||||||||||
| swem⋅er (> swemm⋅er) | |||||||||||||||||||||||||||||||||||||||||||||||||
| swim⋅er | |||||||||||||||||||||||||||||||||||||||||||||||||
| swimmer | |||||||||||||||||||||||||||||||||||||||||||||||||
| Complex word with a root | |||||||||||||||||||||||||||||||||||||||||||||||||
| radik⋅aal | |||||||||||||||||||||||||||||||||||||||||||||||||
| radik(root)⋅ADJZ | |||||||||||||||||||||||||||||||||||||||||||||||||
| radical | |||||||||||||||||||||||||||||||||||||||||||||||||
| Ordinal morpheme | |||||||||||||||||||||||||||||||||||||||||||||||||
| twee·de | |||||||||||||||||||||||||||||||||||||||||||||||||
| [[twee](NUM)[de](ADJZ.ORD)](A) | |||||||||||||||||||||||||||||||||||||||||||||||||
| twee·ADJZ.ORD | |||||||||||||||||||||||||||||||||||||||||||||||||
| second | |||||||||||||||||||||||||||||||||||||||||||||||||
| Ordinal morphemes are considered to be adjectivisers, but the resulting word can be used as adjective or adverb. | |||||||||||||||||||||||||||||||||||||||||||||||||
| Strong past participle | |||||||||||||||||||||||||||||||||||||||||||||||||
| gebroke | |||||||||||||||||||||||||||||||||||||||||||||||||
| break.PST.PTCP | |||||||||||||||||||||||||||||||||||||||||||||||||
| broken | |||||||||||||||||||||||||||||||||||||||||||||||||
| Weak past participle | |||||||||||||||||||||||||||||||||||||||||||||||||
| ge·breek·t·e | |||||||||||||||||||||||||||||||||||||||||||||||||
| PST.PTCP·break·PST.PTCP·ATTR | |||||||||||||||||||||||||||||||||||||||||||||||||
| broken | |||||||||||||||||||||||||||||||||||||||||||||||||
| Compound | |||||||||||||||||||||||||||||||||||||||||||||||||
| tafel+doek | |||||||||||||||||||||||||||||||||||||||||||||||||
| table+cloth | |||||||||||||||||||||||||||||||||||||||||||||||||
| table cloth | |||||||||||||||||||||||||||||||||||||||||||||||||
| Compound with linker | |||||||||||||||||||||||||||||||||||||||||||||||||
| hond·e+hok | |||||||||||||||||||||||||||||||||||||||||||||||||
| dog·LK+cage | |||||||||||||||||||||||||||||||||||||||||||||||||
| kennel | |||||||||||||||||||||||||||||||||||||||||||||||||
| Separable complex verb in present tense | |||||||||||||||||||||||||||||||||||||||||||||||||
| op+gooi | |||||||||||||||||||||||||||||||||||||||||||||||||
| [[op](PREP.PTCL)[gooi](V)](V) | |||||||||||||||||||||||||||||||||||||||||||||||||
| up+throw | |||||||||||||||||||||||||||||||||||||||||||||||||
| to vomit | |||||||||||||||||||||||||||||||||||||||||||||||||
| Separable complex verb in past tense | |||||||||||||||||||||||||||||||||||||||||||||||||
| in+ge·ent (> in+ge·ënt) | |||||||||||||||||||||||||||||||||||||||||||||||||
| in+PST·inoculate | |||||||||||||||||||||||||||||||||||||||||||||||||
| inoculated | |||||||||||||||||||||||||||||||||||||||||||||||||
| Affixoid | |||||||||||||||||||||||||||||||||||||||||||||||||
| hond÷warm | |||||||||||||||||||||||||||||||||||||||||||||||||
| dog÷hot | |||||||||||||||||||||||||||||||||||||||||||||||||
| very hot | |||||||||||||||||||||||||||||||||||||||||||||||||
| Univerbation (only when the centre of discussion) | |||||||||||||||||||||||||||||||||||||||||||||||||
| daar_op | |||||||||||||||||||||||||||||||||||||||||||||||||
| PN_on | |||||||||||||||||||||||||||||||||||||||||||||||||
| on it | |||||||||||||||||||||||||||||||||||||||||||||||||
| Suppletion form | |||||||||||||||||||||||||||||||||||||||||||||||||
| nader | |||||||||||||||||||||||||||||||||||||||||||||||||
| close.CMPR | |||||||||||||||||||||||||||||||||||||||||||||||||
| closer | |||||||||||||||||||||||||||||||||||||||||||||||||
| Blend | |||||||||||||||||||||||||||||||||||||||||||||||||
| storm=kopies (< stormloop=inkopies) | |||||||||||||||||||||||||||||||||||||||||||||||||
| rush=shopping | |||||||||||||||||||||||||||||||||||||||||||||||||
| frantic shopping fever (e.g. in the context of a bidding pandemic) | |||||||||||||||||||||||||||||||||||||||||||||||||
| Contraction | |||||||||||||||||||||||||||||||||||||||||||||||||
| a. | di=s (< dit=is) | ||||||||||||||||||||||||||||||||||||||||||||||||
| it=be.COP | |||||||||||||||||||||||||||||||||||||||||||||||||
| it is / it's | |||||||||||||||||||||||||||||||||||||||||||||||||
| b. | moe=nie (< moet=nie) | ||||||||||||||||||||||||||||||||||||||||||||||||
| must.AUX.MOD=not | |||||||||||||||||||||||||||||||||||||||||||||||||
| mustn't; shouldn't | |||||||||||||||||||||||||||||||||||||||||||||||||
| c. | ek='t (< ek=het) | ||||||||||||||||||||||||||||||||||||||||||||||||
| I=have.AUX | |||||||||||||||||||||||||||||||||||||||||||||||||
| I have | |||||||||||||||||||||||||||||||||||||||||||||||||
| Complex word that is not the centre of discussion | |||||||||||||||||||||||||||||||||||||||||||||||||
| verreweg | |||||||||||||||||||||||||||||||||||||||||||||||||
| by.far | |||||||||||||||||||||||||||||||||||||||||||||||||
| by far | |||||||||||||||||||||||||||||||||||||||||||||||||
| Use this format only when the example/word is not the centre of discussion. | |||||||||||||||||||||||||||||||||||||||||||||||||
| Full morphological analysis | |||||||||||||||||||||||||||||||||||||||||||||||||
| bewerking·s+handleiding OR be·werk·ing·s+hand·leid·ing | |||||||||||||||||||||||||||||||||||||||||||||||||
| [[[[[be](CN)[werk](V)](V)[ing](NMLZ)](N)[s](LK)](N)[[hand](N)[[lei](V)[ing](NMLZ)](N)](N)](N) | |||||||||||||||||||||||||||||||||||||||||||||||||
- Note that there is no space between ANY of the brackets, including between the square brackets and the round brackets.
- The default is to always indicate morpheme boundaries, but it is not always necessary in every example. One would typically indicate morpheme boundaries in an introduction, or otherwise in cases where it is necessary to illustrate some phenomenon.
- When morphological changes are indicated with the > or < symbols, it is also not necessarily required to indicate morpheme boundaries.
- If morpheme boundaries are indicated in the Afrikaans example, the English translation is provided unanalysed. To illustrate similarities in morphological structure, rather use the <morphologicalAnalysis> tag, plus <gloss>.
- Morphosyntactic categories of words are indicated with abbreviations in subscript, e.g. traantjie (N)
- Syntactic structures are presented between square brackets, within which is presented first the syntactic category label, followed by the word or words that instantiate the category, e.g. [(NP) die honde op die passasiersboot] three dogs on a cruise.ship
- By default all functional categories (e.g. N; V; NMLZ; CN) are styled in capital letters (actually small caps).
- Contrary to the style in some of the linguistic literature, meanings are not capitalized (for the sake of readability).
- In morphological analyses, only SEM, which stands for semantics/meaning of, is capitalised.
- Synonymous meanings are separated by comma, while polysemous/homonymous meanings are separated by semicolons, e.g. to mend, repair (clothes); to redress (grievances); to restore (the monarchy); to remedy (an omission); to re-establish, reinstate, bring back.
- In some contexts, conceptualisations are indicated as follows: ; .
If you have any question or suggestions about these notational conventions, please contact Gerhard van Huyssteen.
- 2021/01/06: Added root as abbreviation to use in morphological analyses.
- 2020/04/04: Added notation of curly brackets for subtractive processes.
- 2020/03/11: Clarified formatting of Afrikaans words in titles, headers, keywords and running text.
- 2020/03/07: Added point 9 under "Symbols" under "Morphology", regarding presenting enclitics like ek't (as ek=t I=have.AUX); Numerous glossing examples added under "Morphology"; "Morphology" restructured; Added point 6 under the introduction of "Morphology", regarding different forms of the verb.
- 2020/03/06: Changed bullet lists to numbered lists for ease of reference.
- 2020/02/16: Method for annotating conceptual content (e.g. metaphors) were added (under "Semantics"). Note that this method is yet unconfirmed, and should rather be used sparingly.
- 2020/02/14: Added bullet on using id. as translation for proper names.
- 2020/02/10: Note added on <lexterm><word> for Afrikaans examples allowed in headers (but nowhere else, as has always been the case)
- 2020/02/03: Information on presenting distinctive features added
- 2020/01/10: Changed the manner in which doubtful (?) and ungrammatical (*) examples should be formatted. Previously it was done using attributes; now it should be typed before the example, as part of <wordgroup>.
- 2020/01/07: Under Morphology: Added information about the correct usage of angle brackets to indicate morphonological changes.
- 2020/01/04: Restructured this topic, in order to align with topic to be published publicly
- 2019/12/16: Added info for annotating affixoids.
- 2019/09/29: Added INDEP ("independent") in list of abbreviations.
- 2019/09/03: Added CRD ("cardinal") in list of abbreviations.
- 2019/07/10: Added go.PST (for "is") in list of frequent examples.
- 2019/06/26: Added have.AUX in list of frequent examples, plus information on the particles of particle verbs. Also added some morphological examples.
- 2019/06/13: Added more frequently used examples
- 2019/06/11: Added guidelines for glossing R-pronouns; added <syntacticalAnalysis> to sequence of linguistic material
- 2019/05/27: Editorial changes (no impact on glossing)
- 2019/05/20: Small correction under discussion of participles, where PRS > PST
- 2019/04/05: Three sentences regarding the plus sign (+) and full-stop in glosses added to the 5th bullet under "In-house rules".
- 2018/10/01: Info added on glossing of strong vs. weak participles (bullet four below).
- 2018/09/30: Nothing important changed. Added PTCP.x under common occurring combinations (bullet three below).
- 2018/09/23: Added AB (abstract) and CON (concrete)
- 2018/08/12: Added AP, NP, PP and VP. Note that PP was originally indicated for past/passive participle, but not any more. Contact Gerhard if this change is problematic.
- 2018/07/12: Refined guideline regarding punctuation in glosses and translations.
- 2018/07/12: Added common occurring combinations.
- 2003Introducing linguistic morphologyEdinburgh: Edinburgh University Press
- 2016Die deelwoord as 'n ánder vorm van die werkwoord.Tydskrif vir Geesteswetenskappe5681-101,
- 2016Die deelwoord as 'n ánder vorm van die werkwoord.Tydskrif vir Geesteswetenskappe5681-101,
